최근 SKT에서 발생한 침해사고로 연일 시끌시끌하다. 공격자는 USIM 데이터를 탈취해갔고, 2차 피해가 우려되는 상황이라고 하는데.. 어떻게 진행될지 추이를 지켜봐야 할 것 같다.
이런 저런 기사와 분석 글을 찾다 보니 공격 타임라인이 그려지긴 한다. 먼저 MITRE ATT&CK의 Tactic관점에서 간단하게 살펴보자.
1. 공격 타임라인 생각해보기
이런 APT 공격의 특징은 은밀하고 또 치명적이라는 것이다. 공격자는 수단과 방법을 가리지 않고 최초 침투에 필요한 방법을 동원한다. 이러한 상황에서 가장 좋은 접근 방법은 내가 공격자가 되어 공격자의 관점에서 생각해보는 것이다(공격을 하라는 말은 아니다)
1. Initial Access
파악 불가. (사실 이게 가장 중요하다. 공격자가 어떤 방법으로 최초 침투를 수행했는지) 아마 최초 침투로부터 시간이 오래지났거나, 공격자가 흔적을 삭제했을 경우 최초 침투를 파악하지 못할 공산이 크다.
2. Credential Access
공격자는 최대한 많은 계정 정보와 권한 정보에 접근하려한다. 이를 통해 credential stumping, password spraying공격 등을 수행할 수 있기 때문이다.
이 때 리눅스의 password파일을 크랙하거나, lsa프로세스의 메모리를 dump 하거나, SAM레지스트리 정보를 탈취해 크랙하거나 아니면 키 로거를 설치하거나 하는 등 정말 다양한 방법을 수행할 수 있다. (심지어 다크웹에서 돈주고 사기도 한다)
3. Privilege Escalation
권한 상승은 정상 또는 - 비 정상적인 방법으로 현재 주어진 권한보다 높은 권한을 탈취하는 방법을 말한다.
가령 예를 들어보자면 linux 시스템에서 root권한으로 명령을 수행한다거나, 윈도우 시스템에서 system 권한의 셸을 탈취하는 등의 행위들을 생각해볼 수 있다.
주로 어플리케이션 취약점, 운영체제 misconfiguration, 취약한 계정정보 설정(비밀번호가 쉽다거나, 다 똑같다거나), 운영 체제 취약점 등 정말 다양한 원인이 있다.
운영체제 취약점의 경우 취약점이 발견되면 곧바로 패치가 진행되기 때문에 최신 패치를 적용 하면 이미 알려진 취약점들에 대해서는 상대적으로 안전하지만, 제로데이 취약점에는 방법이 없다.
그리고 실제 구동중인 서비스는 가급적이면 구버전에서 업그레이드 하지 않고 그대로 사용하려는 경향이 강하다. 특히 서버나, 서비스의 경우 업데이트 했다가 서비스가 정상적으로 동작하지 않으면 여러모로 피곤하기 때문에.. 구버전을 그대로 사용하는 경우가 굉장히 많다.
4. Persistance
최초침투-권한 접근-권한 상승 등 과정을 거친 공격자는 자기 자신에게 필요한 정보를 획득할 때 까지 현재 침투한 대상과 은밀하게 연결을 유지하며 지속적으로 정보를 수집했을 것이다. (어떻게 가능했을까? 외부 IP에 대한 접근 제어가 전혀 되지 않았던 상황일까?)
또는 outbound 필터링을 엄밀하게 걸어놓지 않았다면 reverse shell 등의 방법으로 연결을 유지할수도 있다.
5. Lateral Movement
공격자가 탈취해 간 USIM 데이터는 일반적으로 외부로 노출할 필요가 없는 데이터이기 때문에 내부에서만 접근 가능하도록 접근 제어가 되어있었을 것이다. 또한 인가자의 인가된 계정이나, 단말에서만 접근 가능하도록 설정이 되어있었을 가능성이 크다.
이 말은 공격자는 서버 침투 후 Persistance를 유지하며 지속적으로 정보를 수집했다는 말과도 같다. APT공격의 무서움이다.
6. Impact
일반적으로 APT공격은 이 부분에서 발견이 되거나, 여기서도 발견되지 못하면 다크웹 판메글에서 발견이 된다.. 😂 어느정도 규모가 되는 기업이나, 보안 기업에서는 관제팀을 운영한다. 관제팀은 내부-외부 트래픽을 모니터링 하며 이상치를 탐지하는 업무를 수행한다. 다음과 같은 시나리오를 한번 생각해보자.
탐지 시나리오
열심히 일하던 관제팀이 어느 날 내부망에서 약간 이상한 트래픽을 탐지했다.
내부망에서 약 10GB가량의 데이터가 이동 한 것을 탐지했는데, 근무시간이 아니거나, 트래픽이 발생할 노드가 아니거나, DB에서 큰 데이터가 나갔거나 아무튼, 이는 일반적인 상황은 아님이 확실하다.
관제팀이 즉시 보고하고 CERT 전문가들이 출동해서 분석 한 결과 데이터는 이미 탈취되었고, 데이터가 빠져나간 노드를 분석해본다
수상한 파일들과 프로세스가 발견, 분석 결과 BPFdoor backdoor로 확인되었다.
SKT 입장에서는 아마 이런 상황이었을 것이라고 추정된다.
이런 큰 규모의 데이터 유출 사고가 발생하면 공공-민간 합동 분석팀이 꾸려진다. 아마도 국정원, KISA, 금보원 등을 비롯한 각계 전문가들이 지금도 열심히 분석하고있지 않을까?
2. BPFdoor backdoor?
그렇다면이 BPFdoor 백도어가 도대체 뭘까?
BPF는 Berkeley Packet Filter의 약자로, 1992년 Lawrence Berkeley National Laboratory에서 공개된 아주 오래된 기술이다.
BPF의 가장 큰 장점은 커널 레벨에서 동작하기 때문에 가볍고 빠른다는 것이다. 일반적으로 흔히 사용되는 snort, suricata, WAF, 프록시 등은 어플리케이션 레벨에서 동작하기 때문에 일단 모든 패킷을 다 수신하고, 거기서 필터링을 한다. 따라서 패킷을 수신하는데 오버헤드가 발생하며 상대적으로 무겁고 느리다.
하지만 BPF는 패킷의 매직를 넘버 검사한 후 일치하지 않으면 바로 드롭시켜 버릴 수 있다. Unix계열에서는 이 BPF 기능을 커널이 내장하고 있으며 특히 Linux는 BPF 실행을 위한 작은 VM이 커널에 상주하고 있다.
특정 이벤트(패킷 수신 등)가 트리거되면, JIT된 BPF 코드가 실행되어 패킷을 검사하고, 통과한 패킷들만 유저 레벨로 올려 보내는 등 기능을 설정할 수 있다.
또 특정 포트를 오픈하지 않기때문에 netstat이나 ss등 의 도구로는 탐지할 수 없다는 장점도 있다.(공격자 입장에서)
2-1. BPF 실습
BPF에는 클래식 버전인 cBPF가 있고 확장 버전인 eBPF가 있다. 실습에서는 간단하게 eBPF를 사용할 것이다.
| |
14바이트에서 9999 값이 발견되면 터미널에 출력하도록 했다. 왜 14바이트냐면, 이더넷 헤더가 14바이트이기 때문이다.
위 코드를 빌드한 후 LAN환경에서 다음 파이썬 코드를 실행해보자(scapy를 설치해야 한다)
MAC주소는 각자의 환경에 맞게 변경해야 한다.
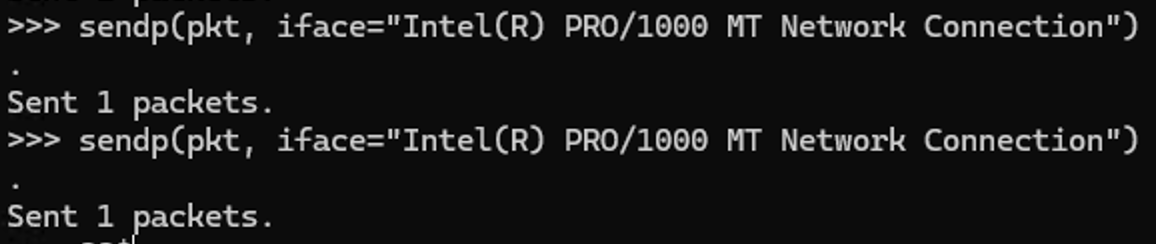

정확하게 잡는 것을 볼 수 있다.
이를 응용하면 OSI 4 레이어까지 올라가볼 수도 있다.
4 레이어에서는 TCP와 UDP 프로토콜이 등장하고 따라서 IP와 Port를 사용한다.
다음과 같이 코드를 수정해보자
| |
4 레이어에서 헤더 크기는 42 bytes 이기 때문에 offset을 변경하고 다시 빌드해주자.
빌드한 파일을 실행하고(root로 실행) 다음처럼 패킷을 설정해서 날리면

위 그림처럼 패킷을 잡는 것을 볼 수 있다.
3. BPFdoor backdoor 코드 분석
BPFdoor backdoor는 cBPF로 작성되어 있다. 전체 코드는 다음 깃허브 주소를 참고하자
https://github.com/gwillgues/BPFDoor
한번에 넣기에는 코드가 길기 때문에(약 800줄) 메인 함수부터 살펴보겠다.
3-1. BPFdoor main 함수
| |
각 함수에는 주석을 달아놓았는데, 이런 저런 함수 호출들은 전부 은닉이나 자식 프로세스 처리에 관련된 코드다.
특히 현재 시각을 시드로 난수를 생성한 후 프로세스 이름을 임의 선택으로 변경해 백도어를 일반적인 프로세스로 위장하고,
또 바이너리 접근시각을 변경하는등 여러가지 탐지 회피 기법이 적용되어 있다.
핵심 기능으로 가려면 packet_loop 함수로 들어가봐야 한다.
3-2. BPFdoor packet_loop 함수
| |
bpf_code[] 라는 배열에 BPF opcode가 작성되어 있다. 다음 표를 참고해서 분석해보자
| Opcode (hex) | Mnemonic | Description |
|---|---|---|
| 0x28 | LDH [k] | Load 2 bytes (halfword) from absolute offset k into A |
| 0x15 | JEQ #k jt jf | If A == k, jump jt; else jump jf |
| 0x30 | LDB [k] | Load 1 byte from absolute offset k into A |
| 0x45 | JSET #k jt jf | If (A & k) != 0, jump jt; else jump jf |
| 0xb1 | TAX | Transfer A to X |
| 0x48 | LDXW [X + k] | Load 2 bytes from offset (X + k) into A |
| 0x50 | LDXMSH [k] | Load byte from offset k, shift left 2, store result in X |
| 0x54 | AND #k | A = A & k |
| 0x74 | SUB #k | A = A - k |
| 0x0c | TAX | Transfer A to X (duplicate encoding of TAX) |
| 0x07 | TXA | Transfer X to A |
| 0x06 | RET #k | Return value k (e.g., 0xFFFF to accept, 0 to drop) |
위 표를 기반으로 bpf_code[] 배열을 다음과같이 분석해 볼 수 있다.
| Line | Opcode | jt | jf | k | Explanation |
|---|---|---|---|---|---|
| 0 | 0x28 | 0 | 0 | 0x0000000c | LDH [12] # Load EtherType |
| 1 | 0x15 | 0 | 27 | 0x00000800 | JEQ #0x0800 # If EtherType == IPv4 |
| 2 | 0x30 | 0 | 0 | 0x00000017 | LDB [23] # Load IP protocol |
| 3 | 0x15 | 0 | 5 | 0x00000011 | JEQ #0x11 # If protocol == UDP |
| 4 | 0x28 | 0 | 0 | 0x00000014 | LDH [20] # Load fragment offset field |
| 5 | 0x45 | 23 | 0 | 0x00001fff | JSET #0x1FFF # If fragmented, drop |
| 6 | 0xb1 | 0 | 0 | 0x0000000e | TAX # A → X |
| 7 | 0x48 | 0 | 0 | 0x00000016 | LDW [X+22] # Load word at (X+22) |
| 8 | 0x15 | 19 | 20 | 0x00007255 | JEQ #0x7255 # Check magic |
| 9 | 0x15 | 0 | 7 | 0x00000001 | JEQ #0x1 # Special check (condition?) |
| 10 | 0x28 | 0 | 0 | 0x00000014 | LDH [20] # Load fragment offset again |
| 11 | 0x45 | 17 | 0 | 0x00001fff | JSET #0x1FFF # Fragmented? |
| 12 | 0xb1 | 0 | 0 | 0x0000000e | TAX # A → X |
| 13 | 0x48 | 0 | 0 | 0x00000016 | LDW [X+22] # Load word at (X+22) |
| 14 | 0x15 | 0 | 14 | 0x00007255 | JEQ #0x7255 # Re-check magic |
| 15 | 0x50 | 0 | 0 | 0x0000000e | LDXMSH [14] # Load length info |
| 16 | 0x15 | 11 | 12 | 0x00000008 | JEQ #0x8 # Protocol ID? |
| 17 | 0x15 | 0 | 11 | 0x00000006 | JEQ #0x6 # Another protocol check |
| 18 | 0x28 | 0 | 0 | 0x00000014 | LDH [20] # Fragment offset again |
| 19 | 0x45 | 9 | 0 | 0x00001fff | JSET #0x1FFF # Fragmented? again |
| 20 | 0xb1 | 0 | 0 | 0x0000000e | TAX # A → X |
| 21 | 0x50 | 0 | 0 | 0x0000001a | LDXMSH [26] # Load byte from offset 26 |
| 22 | 0x54 | 0 | 0 | 0x000000f0 | AND #0xf0 # Mask |
| 23 | 0x74 | 0 | 0 | 0x00000002 | SUB #0x2 # Adjust |
| 24 | 0x0c | 0 | 0 | 0x00000000 | TAX # A → X |
| 25 | 0x07 | 0 | 0 | 0x00000000 | TXA # X → A |
| 26 | 0x48 | 0 | 0 | 0x0000000e | LDW [X+14] # Load word from (X + 14) |
| 27 | 0x15 | 0 | 1 | 0x00005293 | JEQ #0x5293 # Final magic check |
| 28 | 0x06 | 0 | 0 | 0x0000ffff | RET #0xffff # ACCEPT |
| 29 | 0x06 | 0 | 0 | 0x00000000 | RET #0x0 # DROP |
위 BPF 코드의 목적은 다음과 같다
- EtherType 검사 (IPv4만 허용)
- IP Protocol 검사 (UDP / ICMP / TCP 만 허용)
- IP Fragmentation 여부 확인
- 첫 번째 매직 넘버 검사 (X+22)==0x7255?
- (UDP 외) 프로토콜 분기 조건 검사 (ICMP 또는 TCP)
- 두 번째 매직 넘버 검사 (X+14)==0x5293?
- 위 조건 모두 만족 시: RET 0xFFFF → 패킷 수신 (ACCEPT), 아닐 시 RET 0x0000 → 커널에서 패킷 DROP
패킷이 정상적으로 통과되면 최종 목적인 getshell, shell 또는 mon 함수를 호출한한다. 어떻게 셸을 전달하는지도 한번 살펴보자.
3-3. BPFdoor Shell, getShell 함수
getshell 함수부터 살펴보자
| |
iptables 구문이 hex 데이터로 작성되어 있다. 이는 yara 또는 strings등 문자열 탐색을 회피하기 위한 방어 수단이다.
코드 흐름을 살펴보면 먼저 sockfd = b(&toport); 코드를 통해 port를 바인딩한다.
이후 전달받은 IP에 대해 iptables를 이용해 정책 허용, 명령 실행, 정책 삭제 작업을 반복하고 있다.
또 명령을 실행하기 위해 shell 함수를 호출한다. shell 함수를 살펴보자
| |
이 함수에도 역시 문자열 탐지를 회피하기 위해 평문 문자열을 사용하지 않고 hex 데이터를 사용하고 있다.
shell 함수는 실행에 성공하면 write(sock, “3458”, 4); 함수를 실행, 클라이언트에게 3458 문자열을 전송한다.
이후 open_tty 함수를 실행해 터미널을 열고, 만약 터미널 오픈에 실패하면 dub2 함수를 통해 파일 디스크립터 0(표준 입력), 1(표준 출력), 2(표준 오류)를 리다이렉트 한다.
open_tty 함수에서는 ptym_open 함수를 호출하고 /dev/ptmx 파일에 접근한다.
| |
3-4. BPFdoor의 탐지 회피 전략
앞서 살펴본 BPFdoor 코드에는 다양한 악성코드 회피 전략이 숨겨져 있다. 어떤 항목들이 있는지 다시 정리해보자.
T1070.006 - Indicator Removal: Timestomp
setup_time(argv[0]); 코드로 바이너리 파일의 access/modify 시각을 조작한다.
T1036.004 - Masquerading: Masquerade Task or Service set_proc_name(argc, argv, cfg.mask); 코드를 통해 프로세스 이름을 변경하고, 시스템 서비스인 것 처럼 위장한다.
T1027 - Obfuscated Files or Information 평문 문자열을 헥스 데이터로 치환해 문자열 탐지나 yara rule을 회피했다.
이 외에도 터미널 세션 분리, 좀비 프로세스 방지, 등 다양한 기법들이 적용되었는데, 적절한 Mitre ATT&CK 매칭을 찾지 못하겠다.
3-5. ptmx?
ptmx는 pseudo-terminal master multiplexor의 줄임말로 리눅스 시스템에서 psuedo terminal 을 생성할 때 사용된다.
어떤 프로세스가 ptmx를 open하면 해당 프로세스가 psueto terminal master 에 대한 파일 스크립터와 psuedo terminal slave를 취득하고 이것들이 /dev/pts 경로에 생성된다.
grantpt()와 unlockpt() 함수는 ptmx로 생성한 slave PTY를 사용할수 있도록 설정해주는 함수다.
tty를 핸들링 하는 코드도 보이는데, 아마 리눅스 말고 다른 유닉스 계열 운영체제에서도 동작하도록 만든 코드인 것으로 추정된다.
3-6. 그 외 쉘을 확보하는 방법들..
| 방식 | 설명 | 한계점 |
|---|---|---|
execve("/bin/sh", ...) | 기본 쉘 실행. 표준 입출력 설정 없이도 가능 | TTY 없이 실행되면 입출력 문제 발생, 비상호작용 셸만 가능 |
dup2(sock, 0..2) 후 쉘 실행 | 리버스 쉘 구성에서 일반적으로 사용 | vim, top, ssh 등 TTY 의존 프로그램에서 문제 발생 |
setsid() + open("/dev/tty") | 제어 터미널을 새로 확보하여 실행 가능 | 자식 프로세스에 한정, 터미널 세션 생성이 보장되지 않음 |
forkpty() 사용 | glibc/libutil 함수로 PTY 자동 생성 (내부적으로 ptmx 사용) | 외부 의존성 있음, ptmx 사용이 내부에서 일어남 |
socketpair(AF_UNIX, ...) | 유닉스 도메인 소켓으로 표준 입출력 대체 가능 | 완전한 TTY 기능 부족, readline 등 TTY 의존 기능 미작동 |
수동 /dev/pts/N 접근 | 직접 slave PTY를 열어 입출력 연결 | 구현 복잡, grantpt, unlockpt, ptsname 호출 필수 |
4. BPF Door 탐지 방법
다양한 탐지 방법이 있겠는데 하나 하나 소개해보도록 하겠다.
4-1. 시그니처 탐지
가장 단순하면서, 무식한 방법이다.
알려진 악성파일의 hash 를 계산, 이를 모조리 대조해보는 것이다.
이 방법의 장점이라면 이미 알려진 악성 파일에 대해서는 탐지율 100% 라는 것.. 그렇지만 단 1bit의 변화만 있어도 탐지를 할 수 가 없기때문에..
4-2. 프로세스 이름 탐지
위 탐지 방법과 결이 비슷하다. 위의 코드 분석에서 bpf가 다음과 같은 프로세스명으로 자기 자신을 masquerade 하는 것을 볼 수 있었다.
| |
ps -ef 명령을 실행한 후 위 목록과 일치하는 프로세스를 찾아보는 것이다.
4-3. ss -0bp 명령
ss는 socket statistics 의 줄임말로 네트워크 소켓에 대한 정보를 출력하는 명령이다.
필자는 netstat 가 없을때 ss -naotp 명령을 자주 사용한다.
-0bp 옵션은 각각 다음과 같다.
| 옵션 | 롱 옵션 | 의미 | 설명 |
|---|---|---|---|
-0 | --packet | PACKET 소켓만 출력 | 이더넷 레벨의 로우소켓(AF_PACKET). 주로 tcpdump, IDS, eBPF 등에 사용 |
-b | --bpf | BPF 필터가 적용된 소켓 정보 표시 | 소켓에 부착된 BPF 필터 존재 여부를 보여줌 |
-p | --processes | 소켓을 사용하는 프로세스 정보 표시 | 해당 소켓을 사용하는 PID, 프로세스명 등을 출력 |
즉 이 명령은 사용하면 소켓 중 bpf필터가 적용된 것만 프로세스 정보와 함께 출력하라는 의미다. 정말인지 확인해보자.
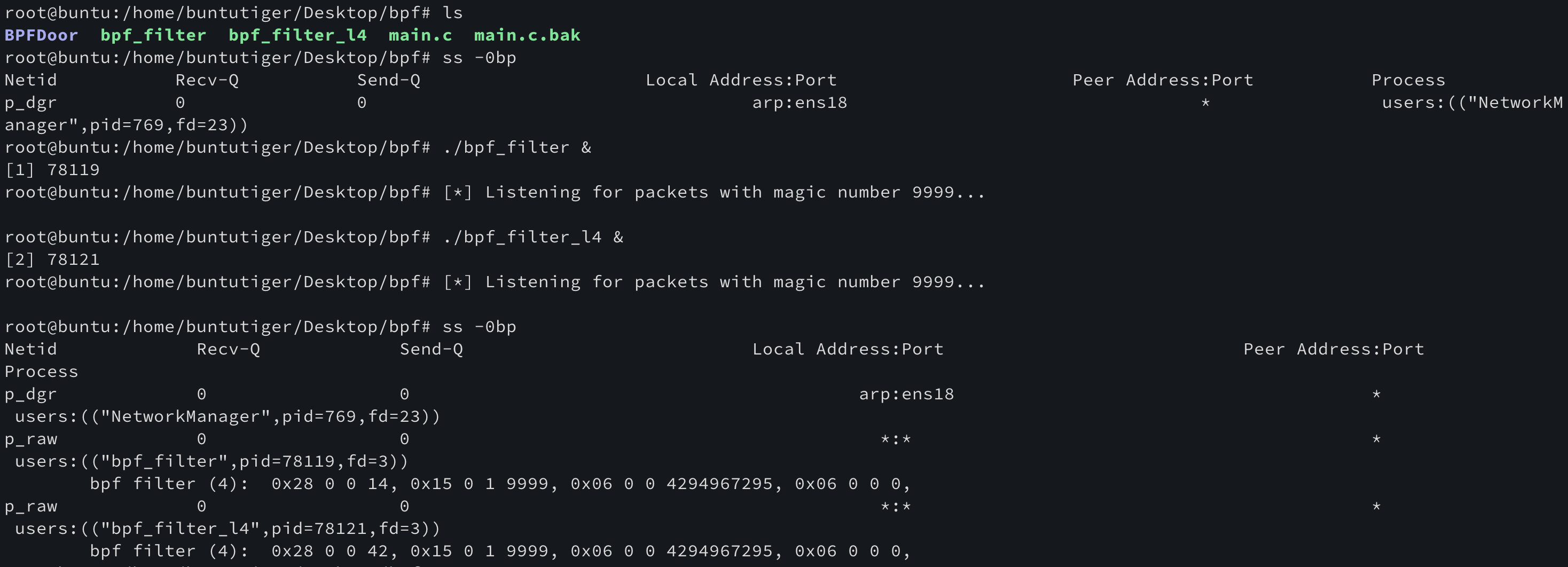
처음에는 bpf 바이너리가 확인되지 않지만, bpf 바이너리 두 개를 실행한 후 다시 ss -0bp 명령을 실행하면 확실하게 실행 파일과 pid를 확인하는 것을 볼 수 있다.
4-4. /proc 경로 분석
리눅스 /proc경로는 현재 실행 중인 프로세스에 대한 정보를 저장하는 가상 파일시스템이다. 즉 다른말로 한다면 어찌됐든 존재하는 모든 프로세스는 /proc 경로에 해당 pid를 가진 디렉토리가 생성되고, 프로세스가 종료되면 디렉토리가 삭제된다.
우리는 /proc 경로에서 몇 가지 파일에 주목할 필요가 있다. 바로 stack, cmdline, exe, cwd 등 이다.
stack 파일에는 프로세스가 실행되면서 호출하는 커널 함수가 기록되어 있다. 또 cmdline 파일에는 프로세스를 실행한 명령이 기록되어 있다.
bpf는 특징적인 커널 함수를 호출하는데 다음 그림을 한번 보시라.
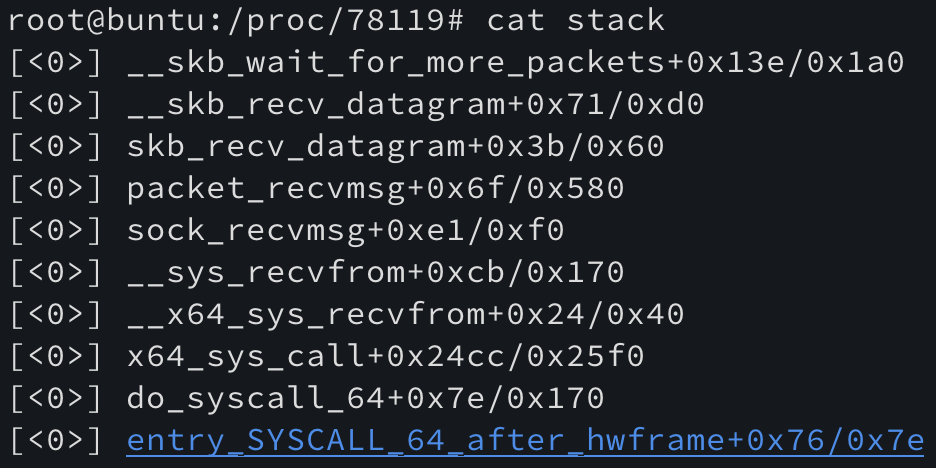
여러가지 스택함수들 중 packet_recvmsg 가 보이는가? 패킷 처리와 관련된 함수인데, 우리는 이 함수를 키워드로 bpf관련 프로세스를 ‘추정’ 해 볼 수 있다. 다음 명령을 실행함으로써 말이다.
| |

또는 grep만 사용할수도 있다.
| |

자 그렇다면 찾은 파일의 실행 명령이나, 경로를 한번에 파악하는 방법도 있지않을까?
find 명령은 파일을 찾는데 정말 유용하다.
매칭되는 stack 파일이 존재하는 경로의 cmdline 파일을 출력하기
| |
매칭되는 stack 파일이 존재하는 경로의 exe(실행파일 심볼릭링크) 가 가리키는 원본 파일 경로 출력하기
| |
매칭되는 stack 파일이 존재하는 경로의 exe(실행파일 심볼릭링크) 가 가리키는 원본 파일 경로를 PID와 함께 출력하기
| |
등 다양하게 활용해 볼 수 있다.
4-5. 그 외 다른 방법들..
다른 방법들도 많이 있지만 여기까지 정도만 소개해도 충분할 것 같다. 나머지는 Reference에 달아놓았으니 참고해보시라
5. 오탐 가능성?
말웨어를 탐지할 때 우리는 항상 오탐과 미탐 문제로부터 벗아날 수 없다. 특히 BPF처럼 시스템에서 지원하는 정상 기능을 악용하는 경우에는 오탐을 항상 염두에 두고 작업해야한다.
만약 어떤 서버가 성능 향상을 위해 BPF기능을 사용하고 있는데, 이를 악성으로 잡아버리면 어떡할것인가?
그래서 프로세스를 종료하고 파일을 삭제했는데, 갑자기 서버의 서비스가 먹통이 되어버리면?
상당히 난처한 상황이 발생할것이다. (이것도 보안사고라 할 수 있다.)
가장 좋은 방법은 분석 전 담당자와의 인터뷰를 통해 대상 서버의 용도가 무엇인지, 어떤 프로그램들이 동작중인지 파악하고 항상 오탐 가능성을 염두에 두는 것이다.
Reference
https://4whomtbts.tistory.com/122
파이오링크 탐지 툴 https://www.piolink.com/kr/service/Security-Analysis.php?bbsCode=security&vType=view&idx=141
한국인터넷진흥원(KISA) 탐지 가이드 https://www.boho.or.kr/kr/bbs/view.do?bbsId=B0000133&pageIndex=1&nttId=71754&menuNo=205020
안랩 분석글 https://asec.ahnlab.com/ko/83742/
트렌드 마이크로 분석 글 https://www.trendmicro.com/en_us/research/25/d/bpfdoor-hidden-controller.html
지니언스 분석 글 https://www.genians.co.kr/blog/threat_intelligence/bpfdoor